How to Collect, Analyze, and Visualize Your API Telemetry Data

API observability is a critical component of managing and maintaining successful APIs. It allows you to gain insights into the performance, availability, and overall health of your APIs. In this article, we will explore the best practices for collecting, analyzing, and visualizing your API telemetry data to ensure optimal API performance and user experience.
Understanding API Observability
API observability refers to the ability to gain insights into the behavior of your APIs by collecting and analyzing telemetry data. It involves monitoring key API metrics, such as response times, error rates, and throughput, to ensure the smooth operation of your APIs.
When it comes to building and maintaining APIs, observability plays a crucial role in ensuring their reliability and performance. By implementing a comprehensive observability strategy, you can effectively monitor and analyze the behavior of your APIs, enabling you to proactively identify and address any issues or anomalies before they impact your users.
But why is API observability so important? Let’s delve deeper into its significance.
Importance of API Observability
Having a comprehensive observability strategy for your APIs is crucial for several reasons.
1. Proactive Issue Identification: Implementing API observability allows for the proactive identification and addressing of issues or anomalies before they impact users. Monitoring key metrics like response times, error rates, and throughput helps detect deviations from normal behavior, enabling timely actions to mitigate disruptions and maintain a seamless user experience.
2. Usage Pattern Understanding: API observability assists in understanding the usage patterns of APIs. Analyzing telemetry data provides valuable insights into how users utilize APIs, enabling informed decisions on scaling and resource allocation. For example, observing a sudden surge in API traffic during specific hours allows for allocating additional resources to ensure optimal performance and user satisfaction.
3. Debugging and Troubleshooting: API observability offers valuable data for debugging and troubleshooting. In the event of an incident or error, detailed telemetry data facilitates quick diagnosis of the root cause and resolution. This reduces the time to resolution, minimizes impact on users, and improves overall system reliability.
4. Actionable Insights: API observability goes beyond mere metric monitoring and data collection. It focuses on gaining actionable insights to drive improvements in API performance, reliability, and scalability.
5. Essential Strategy: Implementing a robust API observability strategy is crucial for organizations relying on APIs to deliver services. Monitoring and analyzing key metrics, understanding usage patterns, and leveraging telemetry data for debugging and troubleshooting ensure the smooth operation of APIs, providing an exceptional user experience.
Best Practices for API Observability
API observability is a critical aspect of ensuring the performance, availability, and reliability of your APIs. Collecting and analyzing telemetry data means that you can gain valuable insights into how your APIs are functioning. You can also identify any issues or bottlenecks that may impact their performance.
Let’s explore some best practices for setting up and maintaining effective API observability.
Setting Up for Success
Before diving into collecting and analyzing API telemetry data, it is important to lay a strong foundation. This involves defining clear objectives for your observability strategy and identifying the key metrics that align with those objectives. By clearly defining what you want to achieve with your observability efforts, you can focus on collecting and analyzing the most relevant data.
Additionally, you should establish robust monitoring and alerting mechanisms to ensure timely detection of any issues. This includes implementing a comprehensive monitoring solution that allows you to track and analyze key metrics such as response times, request rates, and error rates. Real-time monitoring of your APIs can help you detect performance or availability issues so you can promptly take appropriate action to resolve them.
Monitoring and Alerting
Implementing a comprehensive monitoring solution will allow you to track and analyze key API metrics, such as response times, request rates, and error rates. A keen look at these metrics can give you insights into how your APIs are performing and help you identify any potential issues that may impact their availability or performance.
Additionally, setting up alerts based on predefined thresholds will enable you to quickly identify and respond to any deviations from normal behavior. For example, you can set up alerts to notify you when the response time of an API exceeds a certain threshold or when the error rate goes above a specified limit. Timely alerts can help you take immediate action to address any issues and minimize their impact on your APIs.
Troubleshooting and Debugging
Even with a well-monitored API, issues can arise. When problems occur, having the right tools and processes in place to troubleshoot and debug them is essential. This includes logging relevant data, leveraging distributed tracing to understand the flow of requests across services, and using diagnostic tools to investigate and resolve issues efficiently.
Logging relevant data is crucial for understanding what happened leading up to an issue. Capturing detailed logs can help you trace the sequence of events and identify any potential causes of the problem. Additionally, leveraging distributed tracing allows you to visualize the flow of requests across different services and identify any bottlenecks or latency issues.
Using diagnostic tools, such as API testing frameworks or debugging proxies, can also help in investigating and resolving issues efficiently. These tools provide insights into the behavior of your APIs and can help you pinpoint the root cause of any problems.
APIToolkit is one such tool—a robust API management software that ensures that your APIs are performant and reliable.
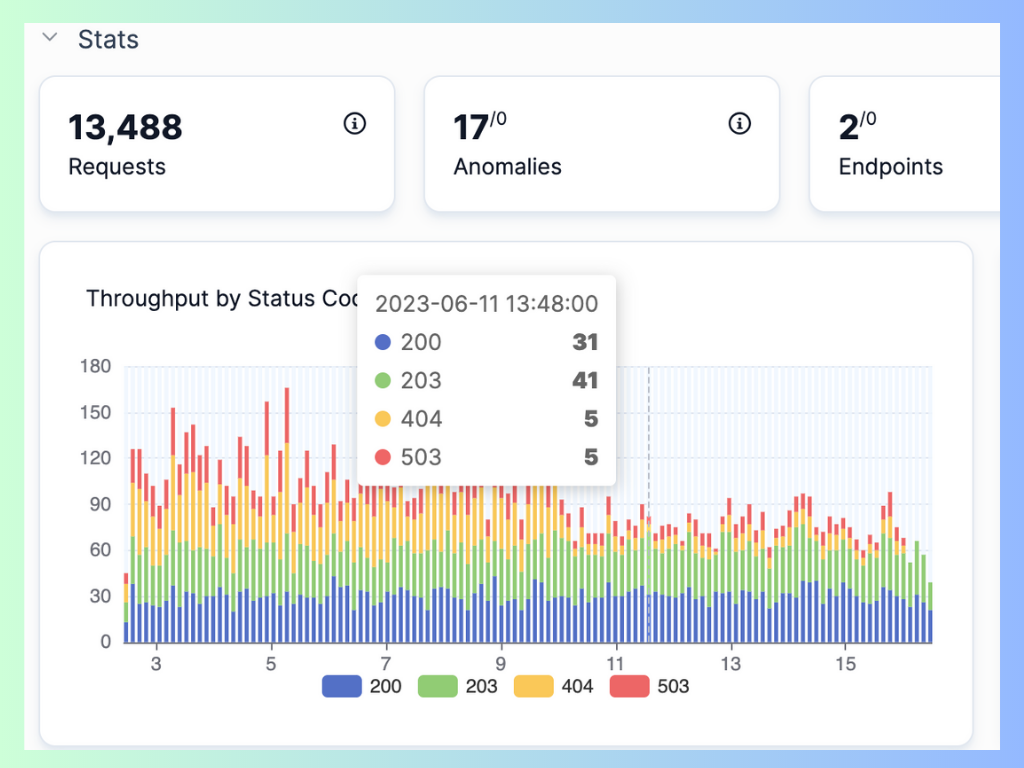
Image Source: APIToolkit’s dashboard displaying throughput by status code.
Collecting API Telemetry Data
When it comes to collecting API telemetry data, there are various types of metrics and logs that can provide valuable insights into the performance and behavior of your API. These metrics and logs can help you identify bottlenecks, track usage patterns, and troubleshoot issues in real time.
Types of API Telemetry Data
Some commonly collected telemetry data includes:
- Response Times: This metric measures the time it takes for your API to respond to a request. Monitoring response times can help you identify slow endpoints or network connectivity issues.
- Request Rates: Tracking the number of requests your API receives over a specific period of time can help you understand the load on your system and plan for scalability.
- Error Rates: Monitoring the frequency of errors occurring in your API can help you identify potential bugs or issues that need to be addressed.
- Latency: Latency measures the time it takes for a request to travel from the client to the server and back. Monitoring latency can help you optimize your API’s performance and improve the user experience.
- Resource Utilization: This metric provides insights into how your API is utilizing system resources such as CPU, memory, and disk space. Monitoring resource utilization can help you identify inefficiencies and optimize performance.
In addition to these metrics, logging events can also provide crucial information about your API’s behavior. For example, authentication failures or database errors can be logged to help you troubleshoot and investigate potential security breaches or data integrity issues.
Tools for Collecting API Telemetry Data
There are several tools available for collecting API telemetry data, each offering different features and capabilities. Some popular choices include:
- APIToolkit: APIToolkit is a powerful API monitoring and observability platform that can help you collect and analyze telemetry data from your API. It offers advanced search and visualization capabilities to help you gain actionable insights.
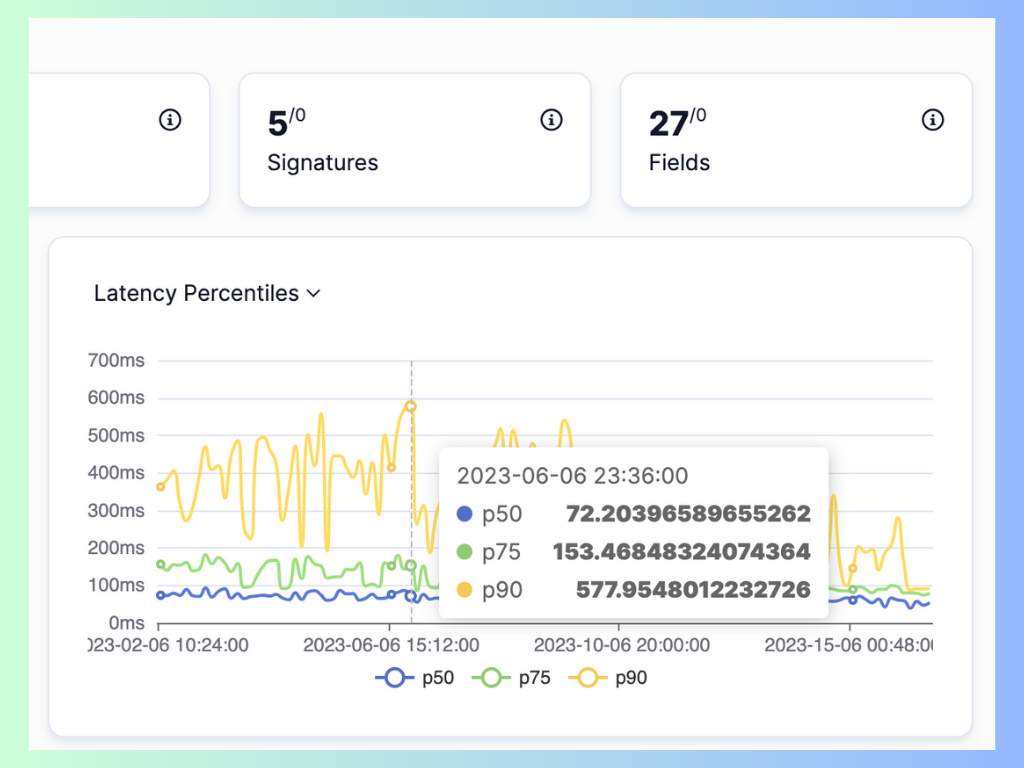 Image Source: APIToolkit’s dashboard displaying latency distribution
Image Source: APIToolkit’s dashboard displaying latency distribution
-
Datadog: Datadog is a log management and analysis tool that provides monitoring and logging capabilities. It allows you to collect, analyze, and visualize telemetry data from your API in real time.
-
New Relic: New Relic offers a range of monitoring and observability solutions, including tools specifically designed for API telemetry data collection. It provides detailed insights into the performance and behavior of your API.
In addition to these observability platforms, cloud service providers like AWS and Google Cloud also offer services that enable you to collect and analyze telemetry data within their respective environments. For example, AWS CloudWatch and Google Cloud’s Stackdriver provide monitoring and logging capabilities that integrate seamlessly with their cloud infrastructure. However, a tool like APIToolkit gives you more granular insight into your APIs and backend services.
By leveraging these tools and services, you can gain valuable insights into the performance, behavior, and usage of your API. This data can help you make informed decisions, optimize your API’s performance, and ensure a seamless experience for your users.
Analyzing API Telemetry Data
Key Metrics to Monitor
When analyzing API telemetry data, it is important to focus on key metrics that provide insights into the performance and usage of your APIs. These metrics typically include:
- Response times
- Error rates
- Throughput, and
- Latency.
By effectively monitoring these metrics, you can detect trends, identify bottlenecks, and take proactive steps to optimize your API performance.
Read: 10 Must-Know API Trends in 2023
Read: Key Benefits of API Integration for Developers (with Statistics)
Data Analysis Techniques
Analyzing API telemetry data requires the use of effective data analysis techniques. These techniques can include visualizing data using charts and graphs to spot patterns and anomalies, performing statistical analysis to identify correlations and trends, and leveraging machine learning algorithms to predict potential issues or optimize performance. By combining these techniques, you can extract meaningful insights from your telemetry data and make data-driven decisions.
Visualizing API Telemetry Data
Benefits of Data Visualization
Visualizing API telemetry data can help communicate and present the analysis results in a clear and intuitive way. Visualizations can also help monitor the current state and health of the API in real time.
Some common types of visualizations for API telemetry data are:
- Charts and graphs that show the distribution and variation of metrics over time or across categories
- Tables and grids that show the values and details of metrics for each dimension or group
- Heatmaps and histograms that show the frequency and intensity of metrics by color or size
- Gauges and meters that show the current value and status of metrics relative to a threshold or target
- Maps and geospatial charts that show the location and density of metrics by region or area
Factors to Consider When Designing Dashboards and Visualizations for API Telemetry Data
- The purpose and audience of your visualization: What are you trying to achieve with your visualization? Who are you trying to inform or persuade with it?
- The type and format of your data: What kind of data are you visualizing? Is it numerical or categorical? Is it continuous or discrete? Is it time-series or event-based?
- The best way to present your data: What kind of chart or graph is most suitable for your data? Is it a line chart, a bar chart, a pie chart, a heatmap, etc.? How can you use colors, shapes, sizes, labels, legends, etc. to enhance your visualization?
- The level of detail and granularity of your data: How much detail do you want to show in your visualization? Do you want to show aggregated or individual data? Do you want to show averages or distributions? Do you want to show absolute or relative values?
- The frequency and duration of your visualization: How often do you want to update or refresh your visualization? Do you want to show real-time or historical data? Do you want to show short-term or long-term trends?
Incorporating alerts and notifications into your visualizations can give you real-time information concerning any critical events or issues that affect your APIs. For example, you can set up thresholds or rules that trigger alerts when certain conditions are met, such as when your API latency exceeds a certain value or when your API availability drops below a certain percentage. You can also configure the channels and methods that you want to use to receive or send the alerts, such as email, SMS, Slack, etc.
Tools for Visualizing API Telemetry Data
To create effective visualizations of your API telemetry data, you need to choose the right tools that offer the features and functionalities you require. Some of the popular visualization tools are APIToolkit, Grafana, Kibana, Splunk, etc.
These tools can help you create dashboards and charts that display various aspects of your API telemetry data, such as request rate, latency distribution, error rate, availability percentage, etc.
Conclusion
The power of predictive analytics and real-time anomaly detection has empowered developers to pre-empt disruptions and proactively optimize performance, ensuring that APIs not only meet but exceed user expectations.
Visualizations and dashboards, akin to windows into your API’s inner workings, enable you to share the story of your API’s journey with different stakeholders. From developers to management teams making strategic decisions, the visual representation of telemetry data paints a vivid picture that fosters alignment and informed decision-making.
Take advantage of observability in microservices architecture to ensure that your API remains adaptable and resilient, ready to navigate the intricacies of our ever-changing digital landscape.
Keep reading
Web API Performance Best Practices: the Ultimate Guide
How to Write API Documentation: 10 Essential Guidelines