Identifying the Root Cause of Application Errors: A Guide to Error Monitoring
One of the pet peeves of a software developer is having to deal with errors. They can be frustrating and costly. Errors can affect the functionality, performance, and security of your application, as well as the satisfaction and loyalty of your users. That’s why error monitoring is an essential practice for any application developer or owner.
In this blog post, we will we will try to cover what error monitoring is, why it is important, and how it can help you identify and resolve the root cause of application errors. We will also cover the different types of application errors, the common causes and examples of them, and the tools and best practices for effective error monitoring.
What are Application Errors?
Application errors are any unexpected or undesired events that occur during the execution of an application. They can be caused by various factors, such as coding mistakes, third-party dependencies, server-related issues, user input, network conditions, etc.
Application errors can have a negative impact on both the user experience and the business outcomes of your application. For example, application errors can:
- Cause your application to crash or freeze
- Display incorrect or incomplete information
- Expose sensitive data or vulnerabilities
- Reduce the speed or responsiveness of your application
- Degrade the quality or functionality of your application
- Lead to user frustration, dissatisfaction, or abandonment
- Damage your reputation or brand image
- Increase your operational costs or revenue loss
Therefore, it is crucial to prevent, detect, and fix application errors as soon as possible.
Different Types of Application Errors
Application errors can be classified into different types based on their nature and severity. Some of the common types of application errors are:
- Runtime errors: These are errors that occur during the execution of an application. They are usually caused by invalid operations, such as dividing by zero, accessing a null object, exceeding an array boundary, etc. Runtime errors can cause your application to terminate abruptly or behave unpredictably.
- Syntax errors: These are errors that occur during the compilation or interpretation of an application. They are usually caused by grammatical or spelling mistakes in the code, such as missing a semicolon, using an undefined variable, mismatching parentheses, etc. Syntax errors can prevent your application from running at all.
- Logical errors: These are errors that occur due to flaws in the logic or algorithm of an application. They are usually caused by incorrect assumptions, wrong calculations, faulty conditions, etc. Logical errors can produce incorrect or unexpected results in your application.
The Role of Error Monitoring
Error monitoring is the process of collecting, analyzing, and reporting on the errors that occur in your application. Error monitoring systems are software tools that help you perform this process automatically and efficiently.
Error monitoring systems can provide you with various benefits, such as:
- Early detection of issues: Error monitoring systems can alert you when an error occurs in your application, so you can investigate and resolve it before it affects more users or causes more damage.
- Improved user satisfaction: Error monitoring systems can help you improve the quality and reliability of your application, which can enhance the user experience and satisfaction. Error monitoring systems can also help you communicate with your users about the status and resolution of errors, which can increase their trust and loyalty.
- Cost-saving in the long run: Error monitoring systems can help you reduce the time and effort required to troubleshoot and fix errors in your application, which can save you money and resources in the long run. Error monitoring systems can also help you prevent future errors by providing you with insights and recommendations on how to improve your code quality and performance.
Identifying Common Application Errors
As we mentioned earlier, there are many possible causes and examples of application errors. However, some of them are more common than others. Here are some of the common causes and examples of application errors:
-
Coding mistakes: These are human errors that occur due to typos, oversights, misunderstandings, or lack of knowledge in coding. Coding mistakes can lead to any type of application error, depending on the context and impact of the mistake. For example:
- Null Pointer Exception: This is a runtime error that occurs when you try to access or manipulate an object that has a null value. This can happen if you forget to initialize an object, assign a null value to an object, or use an object that has been deleted or garbage collected.
- 404 Not Found Error: This is a syntax error that occurs when you try to access a resource that does not exist on a server. This can happen if you misspell the URL, use a broken link, delete or move a file or folder, etc.
- Database Connection Errors: These are logical errors that occur when you try to connect to a database that is unavailable or inaccessible. This can happen if you provide incorrect credentials, use an incompatible driver, exceed the connection limit, etc.
-
Third-party dependencies: These are external factors that affect your application, such as libraries, frameworks, APIs, services, etc. Third-party dependencies can introduce errors in your application if they are incompatible, outdated, buggy, or unavailable. For example:
- Dependency Conflicts: These are errors that occur when you use multiple dependencies that have conflicting or incompatible versions, features, or requirements. This can cause your application to fail or behave inconsistently.
- API Errors: These are errors that occur when you use an API that is unreliable, unstable, or poorly documented. This can cause your application to receive incorrect or incomplete data, or no data at all.
- Service Outages: These are errors that occur when you use a service that is down or overloaded. This can cause your application to lose functionality or performance.
-
Server-related issues: These are factors that affect the environment where your application runs, such as hardware, software, network, etc. Server-related issues can cause errors in your application if they are insufficient, outdated, misconfigured, or compromised. For example:
- Memory Leaks: These are errors that occur when your application consumes more and more memory without releasing it. This can cause your application to slow down or crash.
- Security Breaches: These are errors that occur when your application is attacked or hacked by malicious actors. This can cause your application to expose sensitive data or vulnerabilities, or perform unauthorized actions.
- Network Failures: These are errors that occur when your application is unable to communicate with other components or systems due to network issues. This can cause your application to lose data or functionality.
Error Monitoring Tools and Best Practices
There are many error monitoring tools available in the market, each with its own features and capabilities. Some of the popular error monitoring tools are:
- APIToolkit: APIToolkit is a cloud-based error monitoring tool that helps you track and fix errors in real-time. APIToolkit supports various languages and platforms, such as Python, Java, JavaScript, Ruby, PHP, etc. APIToolkit provides you with rich and detailed error reports, including stack traces, user feedback, breadcrumbs, tags, etc. APIToolkit also integrates with various tools and services, such as GitHub, Slack, Jira, etc.
- Rollbar: Rollbar is another cloud-based error monitoring tool that helps you identify and resolve errors quickly and efficiently. Rollbar supports various languages and frameworks, such as Node.js, React, Angular, Laravel, Django, etc. Rollbar provides you with comprehensive and actionable error insights, including error trends, root causes, impact analysis, etc. Rollbar also integrates with various tools and services, such as Bitbucket, Trello, PagerDuty, etc.
- Raygun: Raygun is a cloud-based error monitoring tool that helps you improve the quality and performance of your application. Raygun supports various languages and technologies, such as .NET, Java, Ruby on Rails, iOS, Android, etc. Raygun provides you with powerful and intuitive error dashboards and charts that show you the frequency, severity, and distribution of errors in your application. Raygun also integrates with various tools and services, such as Azure DevOps, Asana, Twilio, etc.
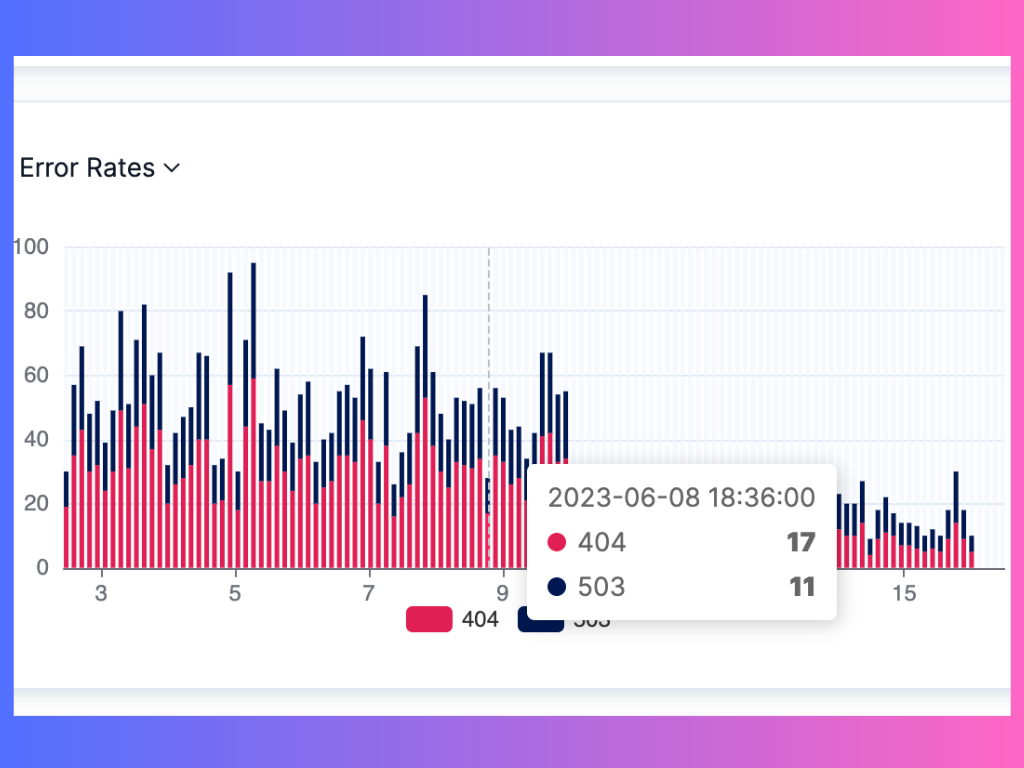 Identifying errors on APIToolkit
Identifying errors on APIToolkit
Read: Key Benefits of API Integration for Developers (with Statistics)
Read: 10 Must-Know API Trends in 2023
Read: API Monitoring and Documentation: the Truth You Must Know
Read: The Key Metrics toMeasiure Developer Success for Your API Platform
How to choose the right error monitoring tool for your application depends on various factors, such as:
- The size and complexity of your application
- The languages and platforms you use
- The features and functionalities you need
- The budget and resources you have
- The preferences and feedback of your team
However, some general criteria that you should consider when choosing an error monitoring tool are:
- Ease of installation and integration
- Accuracy and reliability of error detection and reporting
- Customizability and scalability of error monitoring
- User-friendliness and usability of error interface
- Support and documentation of error tool
Once you have chosen an error monitoring tool for your application, you should implement it effectively to get the most out of it.
Some of the best practices for implementing error monitoring are:
-
Setting up alerts and notifications: You should configure your error monitoring tool to alert you when an error occurs in your application, so you can respond to it promptly. Also, set up notifications to inform you about the status and resolution of errors, so you can keep track of them. APIToolkit integrates with various channels to serve you error alerts and notifications, such as email, Slack, Opsgenie, SMS, push notifications, etc.
-
Integrating with development workflows: You should integrate your error monitoring tool with your development tools and processes, such as code repositories, issue trackers, project management tools, etc. This way, you can streamline your error management workflow and collaborate with your team more effectively. You can also automate some tasks related to error management, such as creating tickets, assigning tasks, updating statuses, etc.
-
Continuous monitoring and analysis: Error monitoring is not only about detecting and reporting errors, but also about analyzing and understanding them. Developers should use error monitoring tools that provide comprehensive and insightful data about errors, such as trends, patterns, root causes, or user feedback. This data can help developers identify the most common or critical errors, find the underlying causes of errors, and measure the impact of errors on the application performance and user satisfaction.
Identifying the Root Cause
Identifying the root cause of an application error is crucial for resolving it effectively and preventing it from recurring. However, finding the root cause can be challenging, especially when dealing with complex or distributed systems. Here are some of the steps that can help you identify the root cause of an error:
-
Review error logs and reports. Error logs and reports are the primary sources of information about errors that occur in an application. They contain detailed information about the error event, such as the time, location, message, stack trace, parameters, environment variables, and user details. Reviewing error logs and reports can help you narrow down the scope of the error, identify potential causes or factors that contributed to the error, and reproduce the error.
-
Reproducing the error. Reproducing the error is the process of recreating the same conditions or scenarios that led to the error occurrence. It can help you verify if the error is consistent or intermittent, isolate the specific component or function that caused the error, and test different hypotheses or solutions for resolving the error.
-
Analyzing code and dependencies. Analyzing code and dependencies is the process of examining the source code and external libraries or services that are involved in the error occurrence. It can help you pinpoint the exact line or statement that triggered the error, identify any bugs or flaws in the code logic or syntax, and evaluate any dependencies or interactions that may have influenced the error.
Mitigating and Resolving Application Errors
A. Developing a strategy for error resolution
The first step in resolving application errors is to have a clear strategy that defines the goals, roles, responsibilities, tools, and processes involved in error monitoring and resolution. A good strategy should answer the following questions:
- What are the key performance indicators (KPIs) and service level objectives (SLOs) for the application?
- What are the sources of error data, such as logs, metrics, traces, alerts, etc.?
- What are the tools and platforms used for error monitoring, analysis, and reporting?
- Who are the stakeholders and owners of the application and its components?
- How are errors communicated and escalated within the team and across the organization?
- How are errors documented and tracked throughout their lifecycle?
- How are errors resolved and verified?
By having a well-defined strategy, the team can ensure that errors are detected, reported, and resolved in a timely and consistent manner.
B. Prioritizing and categorizing errors
Not all errors are equally important or urgent. Some errors may have a high impact on the user experience or the business outcomes, while others may have a low impact or no impact at all. Therefore, it is important to prioritize and categorize errors based on their severity, frequency, scope, and root cause.
A common way to prioritize errors is to use the following matrix:
| Impact | High | Low | |
|---|---|---|---|
| Frequency | High | Critical | Minor |
| Low | Major | Trivial |
Another way to categorize errors is to use the following taxonomy:
- Syntax errors: These are errors that result from incorrect syntax or grammar in the code. They are usually easy to detect and fix by using code editors, compilers, or interpreters.
- Logic errors: These are errors that result from incorrect logic or algorithm in the code. They are usually harder to detect and fix by using debugging tools, testing frameworks, or code reviews.
- Runtime errors: These are errors that occur during the execution of the code. They are usually caused by external factors such as input data, network conditions, hardware failures, etc. They are usually detected by using monitoring tools, logging systems, or exception handlers.
- Configuration errors: These are errors that result from incorrect configuration or settings of the code or its dependencies. They are usually caused by human error, environment changes, or compatibility issues. They are usually detected by using configuration management tools, version control systems, or deployment pipelines.
By prioritizing and categorizing errors, the team can allocate resources and efforts accordingly and focus on resolving the most critical and frequent errors first.
C. Implementing fixes and improvements
The next step in resolving application errors is to implement fixes and improvements that can address the root cause of the errors and prevent them from recurring. Depending on the nature and scope of the error, there are different types of fixes and improvements that can be applied:
- Hotfixes: These are quick and temporary fixes that can be applied directly to the production environment without going through the normal development cycle. They are usually used for critical errors that require immediate resolution.
- Patches: These are small and incremental fixes that can be applied to the existing version of the code without introducing major changes or features. They are usually used for major errors that require prompt resolution.
- Updates: These are large and comprehensive fixes that can introduce new features or changes to the existing version of the code. They are usually used for minor or trivial errors that require regular resolution.
- Upgrades: These are major and transformative changes that can replace the existing version of the code with a new one. They are usually used for errors that require occasional resolution or for strategic reasons.
When implementing fixes and improvements, the team should follow the best practices of software development, such as:
- Writing clean, readable, and maintainable code
- Following coding standards and conventions
- Testing and debugging the code thoroughly
- Documenting and commenting the code properly
- Reviewing and approving the code by peers
- Deploying and releasing the code safely and securely
D. Continual monitoring and reevaluation
The final step in resolving application errors is to continually monitor and reevaluate the application performance and user feedback. This can help verify that the fixes and improvements have been effective and have not introduced new errors or issues. It can also help identify new opportunities for optimization and enhancement.
Conclusion
Application errors are inevitable, but they can be mitigated and resolved by following a systematic approach to error monitoring and resolution. By developing a strategy, prioritizing and categorizing errors, implementing fixes and improvements, and continually monitoring and reevaluating the application performance, the team can deliver a high-quality and reliable application that satisfies both users and stakeholders.
Also Read:
Best API Monitoring and Observability Tools in 2023
How to Write API Documentation: 14 Essential Guidelines
Ultimate Guide to API Testing Automation
Web API Performance Best Practices - the Ultimate Guide